SafeBehavior: Simulating Human-Like Multistage Reasoning to Mitigate Jailbreak Attacks in Large Language Models
A Novel Hierarchical Jailbreak Defense Framework via Human-Like Multistage Reasoning

Abstract
Large Language Models (LLMs) have achieved impressive performance across diverse natural language processing tasks, but their growing power also amplifies potential risks such as jailbreak attacks that circumvent built-in safety mechanisms. Existing defenses including input paraphrasing, multi step evaluation, and safety expert models often suffer from high computational costs, limited generalization, or rigid workflows that fail to detect subtle malicious intent embedded in complex contexts. Inspired by cognitive science findings on human decision making, we propose SafeBehavior, a novel hierarchical jailbreak defense mechanism that simulates the adaptive multistage reasoning process of humans. SafeBehavior decomposes safety evaluation into three stages: intention inference to detect obvious input risks, self introspection to assess generated responses and assign confidence based judgments, and self revision to adaptively rewrite uncertain outputs while preserving user intent and enforcing safety constraints. We extensively evaluate SafeBehavior against five representative jailbreak attack types including optimization based, contextual manipulation, and prompt based attacks and compare it with seven state of the art defense baselines. Experimental results show that SafeBehavior significantly improves robustness and adaptability across diverse threat scenarios, offering an efficient and human inspired approach to safeguarding LLMs against jailbreak attempts.
Our Insight
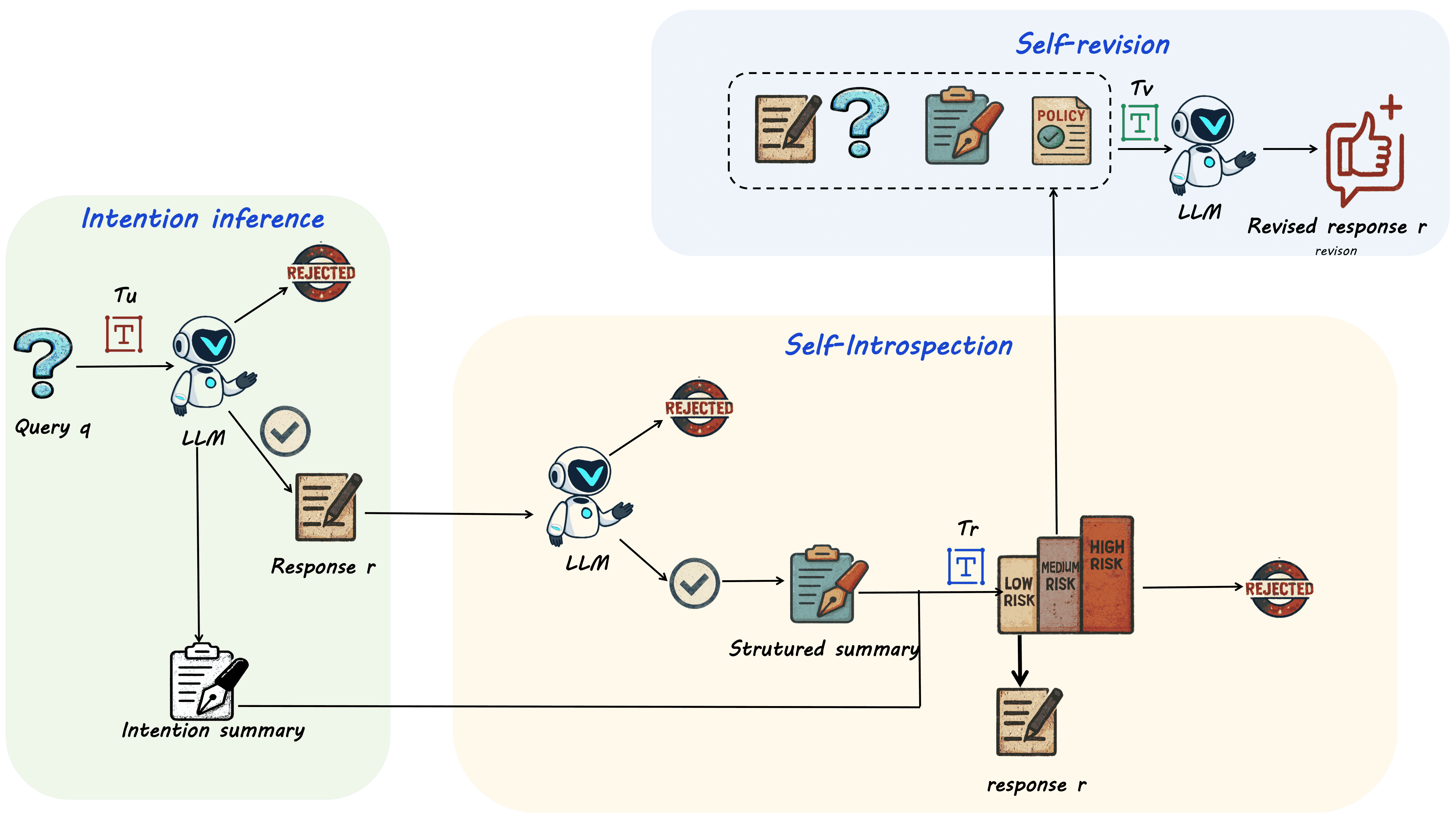
SafeBehavior is a hierarchical defense framework designed to simulate the multistage reasoning process of humans when confronted with inappropriate language or jailbreak prompts. Instead of relying on static, single-pass defenses, SafeBehavior dynamically evaluates user input and model output across three adaptive stages to ensure both safety and usability.
🔍 Three-Stage Human-Like Defense Process
 1. Stage I – Intention Inference
1. Stage I – Intention Inference
- Goal: Perform a fast, coarse-grained scan of the input prompt to identify any clear malicious intent or harmful topics.
- Mechanism: The model uses an intent decomposition template to summarize the user's goal and extract harmful entities.
- Outcome: If flagged harmful, the process is terminated early to avoid unsafe output.
 2. Stage II – Self-Introspection
2. Stage II – Self-Introspection
- Goal: Perform structured introspection on the model's own generated response to assess potential jailbreak risks.
- Scoring: The model produces a jailbreak confidence score
Sr∈ [0, 1], based on risk patterns, harmful entities, and policy violations. - Decision: Responses are accepted, refused, or sent for revision based on thresholds
τand1 - τ.
 3. Stage III – Self-Revision
3. Stage III – Self-Revision
- Goal: Handle ambiguous or borderline unsafe responses by rewriting them to preserve user intent while enhancing safety.
- Mechanism: A revision template guides the model to rephrase the response using the original prompt and jailbreak policy.
- Outcome: Generates safe yet informative outputs even in complex edge cases.
✅ Why It Works
- Adaptive Decision-Making: The three-stage process mimics human judgment, enabling fine-grained control over harmful or ambiguous prompts.
- Flexible Output Handling: Instead of rigid refusal, uncertain responses can be revised for better safety/utility trade-offs.
- Minimal Overhead: The system only engages deeper reasoning stages when necessary, preserving efficiency.
- Defense Generalization: Achieves strong performance across multiple jailbreak attack types, including optimization-based, contextual, and prompt-based attacks.
Try it
SafeBehavior Demo
Experiments
Experimental Setup
We conduct comprehensive evaluations of SafeBehavior across multiple dimensions to assess its effectiveness against jailbreak attacks while preserving model utility. Our experimental framework includes:
- Attack Types: Five representative jailbreak attack categories including optimization-based attacks (GCG), contextual manipulation (Deep Inception), prompt engineering (Bypass, IFSJ), and multi-turn conversational attacks (Siege)
- Defense Baselines: Seven state-of-the-art defense methods including Paraphrase, Intention Analysis, Self-Examination, Retokenization, SafeDecoding, and other recent approaches
Main Results
SafeBehavior demonstrates superior performance across all evaluated attack scenarios, significantly outperforming existing defense mechanisms while maintaining high model utility for legitimate use cases.
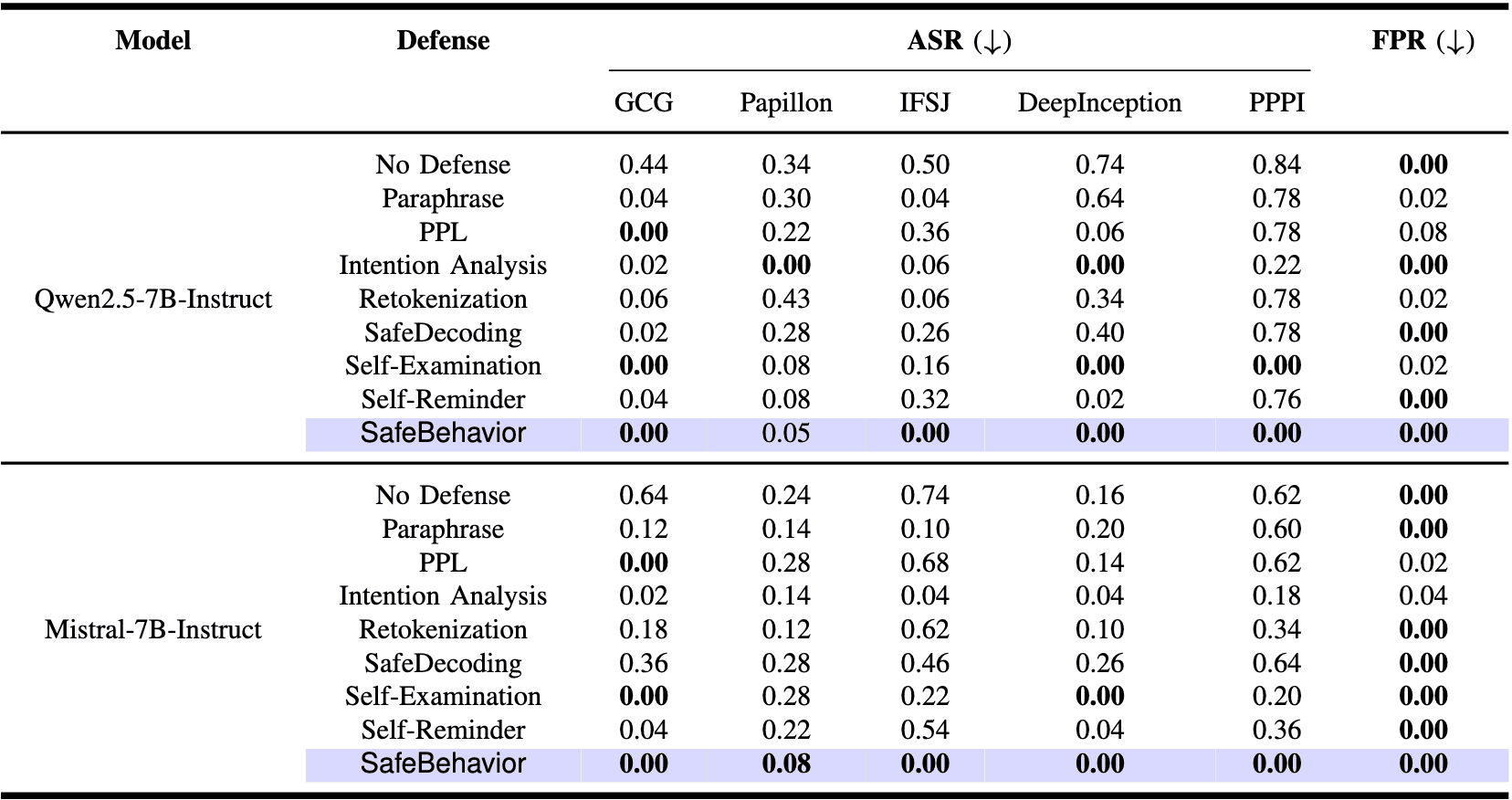
Table 1 presents the comprehensive evaluation results across five major attack categories. SafeBehavior achieves consistently low Attack Success Rates, with particularly strong performance against sophisticated attacks like GCG optimization and Deep Inception contextual manipulation. The hierarchical three-stage framework effectively identifies and mitigates both direct and subtle adversarial attempts while preserving response quality for legitimate user queries.
Multi-turn Attack Robustness

Table 2 evaluates defense robustness against multi-turn Siege attacks, where adversaries attempt to gradually compromise the model through extended conversations. Traditional single-stage defenses such as Paraphrase, Intention Analysis, and Self-Examination show significant degradation in later rounds, with ASR values climbing from moderate initial performance to 0.82-0.96.SafeBehavior maintains consistently robust performance with ASR values between 0.12-0.14 across all conversation rounds, demonstrating the effectiveness of its adaptive multi-stage reasoning approach for sustained adversarial interactions.
Utility Preservation Analysis
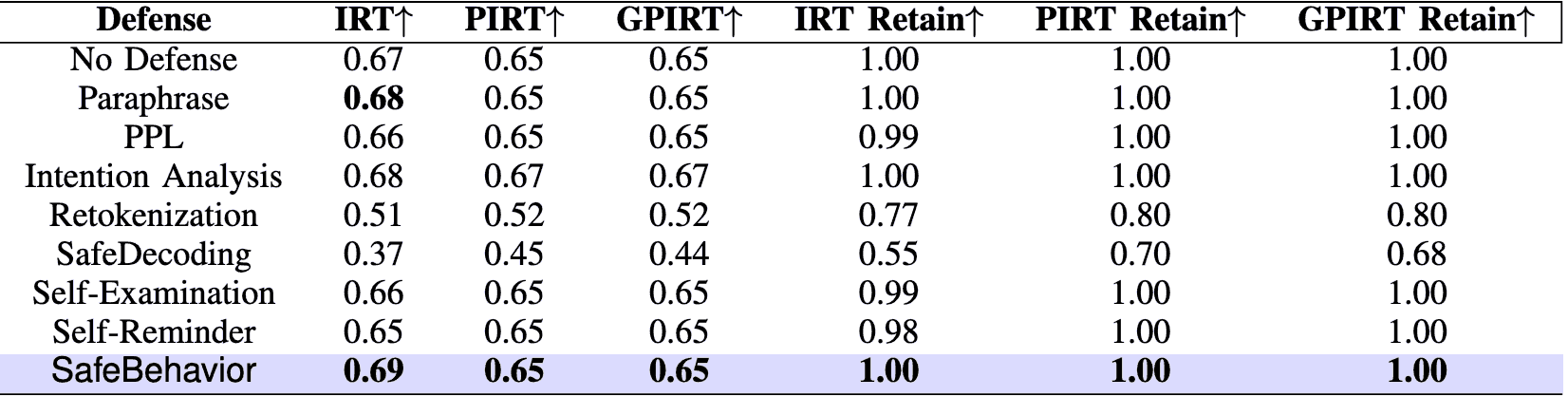
Table 3 analyzes the critical balance between security and utility preservation. Many existing defense mechanisms achieve security at the cost of significantly degraded model performance, with methods like Retokenization and SafeDecoding showing substantial drops in reasoning capabilities and retain ratios.SafeBehavior uniquely achieves optimal security-utility balance, maintaining retain ratios of 1.00 across all evaluation metrics while slightly improving certain reasoning scores. This demonstrates that our adaptive multi-stage approach effectively distinguishes between malicious and legitimate queries without compromising model utility.
Key Findings and Analysis
Our comprehensive experimental evaluation reveals several important insights:
- Stage Effectiveness: Each of the three stages contributes meaningfully to overall defense performance, with the intention inference stage catching obvious attacks early and the self-revision stage handling subtle edge cases
- Adaptive Thresholding: The confidence-based decision making in stage II enables flexible security-utility trade-offs based on deployment requirements
- Generalization: Strong performance across diverse attack types and model architectures demonstrates the robustness of the human-inspired reasoning approach
- Computational Efficiency: The hierarchical design minimizes computational overhead by only engaging deeper reasoning stages when necessary
The experimental results conclusively demonstrate that SafeBehavior represents a significant advancement in LLM security, offering superior protection against sophisticated jailbreak attacks while preserving model utility for legitimate applications. The human-inspired multi-stage reasoning framework provides both immediate practical benefits and a promising foundation for future research in adaptive AI safety mechanisms.
Conclusion
In this paper, we introduced SafeBehavior, a novel hierarchical jailbreak defense mechanism that simulates human-like multistage reasoning to mitigate adversarial attacks against Large Language Models. By implementing a three-stage framework consisting of intention inference, self introspection, and self revision, our method successfully addresses the limitations of existing defense approaches, including high computational costs, limited generalization, and rigid workflows that fail to detect subtle malicious intent. Comprehensive experiments across diverse jailbreak attack scenarios demonstrated the significant effectiveness of SafeBehavior, surpassing existing state-of-the-art defense mechanisms in both robustness and adaptability. Our results highlight the critical role of human-inspired reasoning strategies for building robust and safe AI systems.
📖Cite Us
@misc{zhao2025safebehaviorsimulatinghumanlikemultistage,
title={SafeBehavior: Simulating Human-Like Multistage Reasoning to Mitigate Jailbreak Attacks in Large Language Models},
author={Qinjian Zhao and Jiaqi Wang and Zhiqiang Gao and Zhihao Dou and Belal Abuhaija and Kaizhu Huang},
year={2025},
eprint={2509.26345},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.26345},
}